

前回の記事では、WEBカメラの画像を表示して、ボタンを押すと任意のフォルダに保存するアプリケーションを作りました。
今回の記事では、そのアプリを改造して、画像内にガイド(矩形・四角)を表示してその範囲を別の画像ファイルとして保存するように改造しました。
改造の理由
AI学習用画像データの取得は一度にできないので、毎回同じサイズと範囲で画像を取得したく、ガイドを表示できれば、はかりの位置調整でばらつきを少なく画像が取得できるからです。
ガイド表示機能は、AI学習後の推論時も同じ位置にはかりを調整する必要があるので、後々必要になる機能だからです。
ガイド内範囲を画像を別ファイルで保存しようと思ったのは、オリジナル画像(大きな画像)から、後で切り出すより、オリジナル画像を保存すると同時に切り出せばのちの処理が少なくなると考えました。
アプリケーションと保存した画像
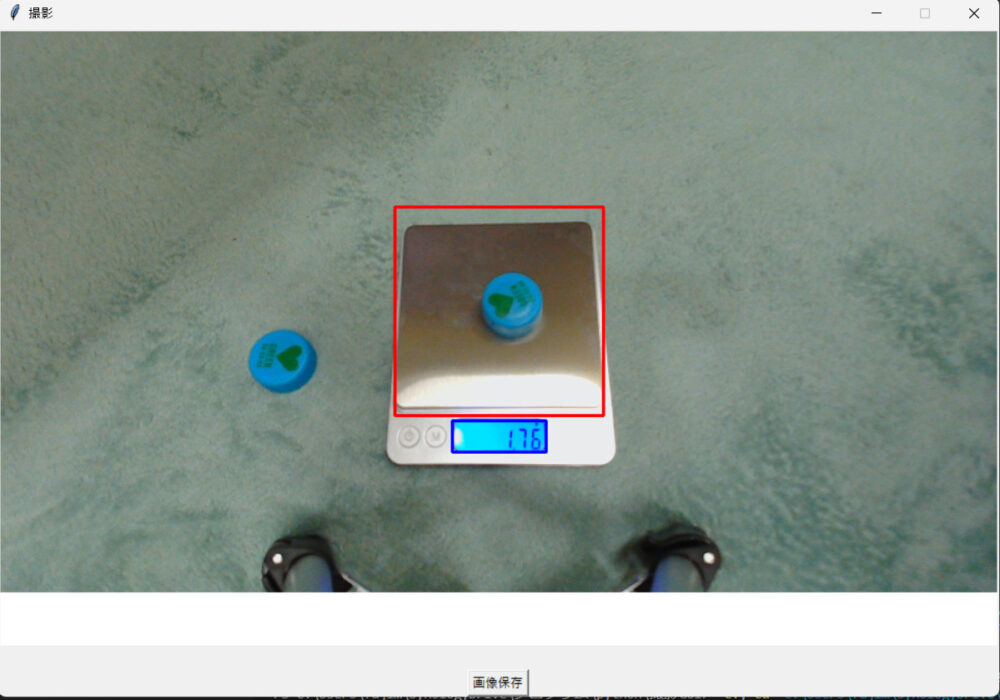
アプリケーションの画面です。アプリケーション画面上のはかり計測部分に赤色のガイド、重さの表示部に青色のガイドを表示しています。
アプリケーション下部の画像保存ボタンを押すと下記の3種類の画像を指定したフォルダに保存します。

オリジナル画像

計測部画像

計測数値表示画像
改造したpythonコード
実際に改造したコードを開示します。
コピーして使用される場合には、outfol=の行で画像を出力したいフォルダパスを設定してください。
import sys
import cv2
import os
import datetime
import tkinter as tk
from PIL import Image, ImageTk
import numpy as np
outfol = ''#ここに画像を出力するフォルダのパスを入力してください
def imwrite(filename, img, params=None):
try:
ext = os.path.splitext(filename)[1]
result, n = cv2.imencode(ext, img, params)
if result:
with open(filename, mode='w+b') as f:
n.tofile(f)
return True
else:
return False
except Exception as e:
print(e)
return False
class Application(tk.Frame):
def __init__(self, master=None):
super().__init__(master)
self.master = master
self.master.title(u"撮影")
self.master.geometry("960x640") # ウィンドウサイズ X1920/2 Y1080/2+100
self.master.resizable(width=False, height=False)
self.canvas = tk.Canvas(master, width=960, height=540, bg="white") # キャンバスサイズをHDの半分に設定
self.canvas.pack(side=tk.TOP, fill=tk.BOTH, expand=True)
# ラベルの初期化
self.label1_text = tk.StringVar()
self.label1_text.set("") # 初期値を空に設定
# ラベルを作成
self.label1 = tk.Label(self.master, textvariable=self.label1_text)
self.label1.pack(side=tk.TOP)
self.capStart()
self.create_widgets()
def update(self):
global p_img
global p_frame
global p_org
global p_red
global p_blue
ret, p_frame = cap.read()
if ret:
# ウェブカメラから取得したフレームをHDサイズの半分にリサイズ
p_org=p_frame
p_frame = cv2.resize(p_frame, (960, 540))
# 画像上に赤色矩形を描画
rect_size = 200
center_x, center_y = 960 // 2, 540 // 2
top_left = (center_x - rect_size // 2, center_y - rect_size // 2)
bottom_right = (center_x + rect_size // 2, center_y + rect_size // 2)
cv2.rectangle(p_frame, top_left, bottom_right, (0, 0, 255), 2) # 赤い枠を描画
# 赤い矩形部分を切り出し
p_red = p_frame[center_y - rect_size // 2:center_y + rect_size // 2, center_x - rect_size // 2:center_x + rect_size // 2]
# 画像上に青色矩形を描画
blue_width=90
blue_height=30
blue_x_center=960//2
blue_y_center=540//2+100+20
b_top_left=(blue_x_center-blue_width//2,blue_y_center-blue_height//2)
b_bottom_right=(blue_x_center+blue_width//2,blue_y_center+blue_height//2)
cv2.rectangle(p_frame, b_top_left, b_bottom_right, (255, 0, 0), 2) # 青色枠を描画
p_blue=p_frame[blue_y_center-blue_height//2:blue_y_center+blue_height//2,blue_x_center-blue_width//2:blue_x_center+blue_width//2]
p_img = ImageTk.PhotoImage(Image.fromarray(cv2.cvtColor(p_frame, cv2.COLOR_BGR2RGB)))
self.canvas.create_image(960 // 2, 540 // 2, image=p_img)
else:
print("u-Fail")
self.label1_text.set("カメラからの映像取得に失敗しました")
self.master.after(50, self.update)
def button1_clicked(self, event):
strtime = '{0:%Y%m%d%H%M%S}'.format(datetime.datetime.now())
imwrite(outfol + '/' + strtime + '.jpg', p_org)
imwrite(outfol + '/r_' + strtime + '.jpg', p_red)
imwrite(outfol + '/b_' + strtime + '.jpg', p_blue)
self.label1_text.set("画像を保存しました: " + strtime + ".jpg")
def create_widgets(self):
button1 = tk.Button(self.master, text=str(u"画像保存"))
button1.bind("<1>", self.button1_clicked)
button1.pack(side=tk.TOP)
self.update()
def capStart(self):
print('camera-ON')
try:
global cap
# ウェブカメラの解像度を設定
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1920)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 1080)
except Exception as e:
print("error:", e)
cap.release()
cv2.destroyAllWindows()
def main():
root = tk.Tk()
app = Application(master=root)
app.mainloop()
if __name__ == "__main__":
main()
今後の改造について
開示したコード中に、はかりの測定部の画像切り出しとデジタル表示部の切り出しの機能を追加していますが、現在は切り出した後にソフトウェア画面には表示していません。
AI判定ができるようになったら、その機能を活用予定です。
今回の改造で、はかりのデジタル表示部の画像が取得できるようになったので、次回の改造ではそのデジタル表示をOCRで数値に変換できる機能を開発しようと思います。


コメント