

pythonを使用してのWEBスクレイピングはやったことがあったので、ExcelVBAで同じ結果を得るために、環境構築やコードの記述等、どちらがやり易いかを検証してみました。
ExcelVBAでのスクレイピングは、インターネットエクスプローラを使用している実例がweb上にたくさんありましたが、インターネットエクスプローラは廃止になりましたので、今回はpythonもExcelVBAもchromeを使用して比較検証を行います。
スクレイピングでwebページからデータを取得する実例コードが確認したい方は目次から該当する部分へジャンプして確認してください。
比較検証結果
結論からお伝えすると、pythonを使ったことが無くて、ExcelVBAが得意な方以外は、pythonをおすすめします。
| python | ExcelVBA | |
| 処理時間 | 5.21秒 | 7.60秒 |
| 実行環境 | pythonをインストール必要 | Excelがインストールされていたら実行可能 |
| seleniumインストール | ◎ (pip install) | △手間がかかる .NET Frameworkもインストール必要 |
| webdriver管理 | ◎ (pip install) | △インストール必要 |
| エクセルへの記述 | 〇 | ◎ |
| selenium操作 | 同程度 | 同程度 |
pythonをおすすめする理由
- seleniumとwebdriver管理のためのライブラリ(プログラム)をインストールする手間が圧倒的に少ないこと
- 処理時間が短いこと
自分一人だけでスクレイピングプログラムを使用する場合は、インストールなどの設定が1度きりなので良いのですが、複数台のPCにプログラムを配布するのであれば、インストールの手間が大きな差になりそうです。
ExcelVBAでのメリットは、エクセルに結果を出力した後に、エクセルに対して処理を行う場合に処理がしやすい点です。(例:並び替えや罫線を引くなど)
seleniumでのスクレイピングプログラムのコーディングは多少差があるものの、難易度は同程度と感じました。
検証について
この記事のこれより下は、実際に検証した過程や実際のコードを公開しています。
途中でエラーが発生したりしましたので、おそらくスクレイピングを初めてExcelVBAで行う場合に参考になると思います。
これからスクレイピングプログラムを作成しようとする方は最後まで読んでいただけると嬉しいです。
スクレイピングしても良いサイトか確認する方法
まずは、スクレイピングするにあたって、対象のサイトがスクレイピングを禁止されていないかを確認します。
- サイトによってはAPIを提供している場合があり、API機能を利用すればスクレイピングしなくてもデータを取得することができる場合があります。その場合にはスクレイピングせずAPIを利用ください。
- 利用規約にスクレイピングが禁止されていないかを確認ください。
- スクレイピングを禁止しているかは「robots.txt」で確認することができます。
今回は鉄鋼新聞の市中相場の値を取得するようにスクレイピングをおこないます。
実際に鉄鋼新聞のページで確認してみました。
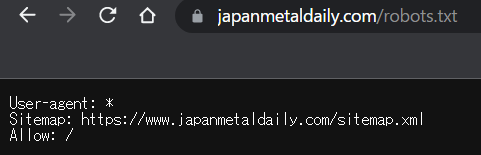
User-agent: 対象とするクロールの種類です。
Disallow: クロールを禁止するパスです。
Allow: クロールを許可するパスです。
Sitemap: XMLサイトマップのURLです。
鉄鋼新聞のサイトではすべてのクロールにおいて、クロール(スクレイピング)は禁止されていないようです。
スクレイピングを禁止されていないサイトであっても、サーバーへの負荷をかけないように良識の範囲内でスクレイピングを実行してください。
サーバーへの負荷がかかる処理とは、短時間で何度もサイトにアクセスや検索実行をする等です。
繰り返し処理でサーバーに接続する場合には、waitなどの待機処理をコードに追加して対策下さい。
スクレイピング処理共通項目
ExcelVBAとpythonで処理する内容で共通する項目を記述します。
seleniumを使用します。(ExcelVBAはselenium Basicをインストールして使用します。)
ブラウザはgoogle chromeを使用します。
鉄鋼新聞の市中相場のwebページから調査項目の東京と大阪の高値と安値をそれぞれ取得して、結果をtext.xlsxの該当するセルに転記します。

pythonでの構築実例
それでは実際にpythonのコードを記述して実行しほしい結果が得られるように構築していきましょう。
python自体はすでにインストール済みという前提で進めます。
今回のプログラムに必要なライブラリ3つをpipインストールします。コマンドプロンプトにて下記3行を実行してください。
pip install webdriver-manager
pip install selenium
pip install openpyxlライブラリの簡単な説明をしておきます。
- webdriver-managerはchromeのwebdriverのバージョンをchromeのバージョンに合わせて自動的に取得するライブラリです。このライブラリを導入するまでは、chromeのバージョンアップのたびに手動でダウンロードする必要がありました。
- seleniumはwebブラウザの操作を自動化(プログラムで操作)するライブラリです。
- openpyxlはpythonでExcelファイルを操作するためのライブラリです。
スクレイピングpythonコード
ライブラリの説明が終わりましたので、実際にpythonのコードを公開します。
#市中相場価格調査
from webdriver_manager.chrome import ChromeDriverManager #chromedriverの自動更新ライブラリ
from selenium import webdriver
from tkinter import messagebox
import os
import datetime
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import openpyxl #エクセル用ライブラリ
def main():
#chromeをオープン
chro = webdriver.Chrome(ChromeDriverManager().install())
#エクセルファイル読み込み
input_excelfile_name=os.path.dirname(__file__)+'/test.xlsx'
wb = openpyxl.load_workbook(input_excelfile_name)
sheet=wb['データ'] #エクセルのデータシートを取得
sheet_max_row=sheet.max_row
#webページ取得
chro.get('https://www.japanmetaldaily.com/list/market/details/')
WebDriverWait(chro, 10).until(EC.presence_of_element_located((By.CLASS_NAME,'market-detail-list__table')))#調査対象のテーブルが表示されるまで待機
market_d_list=chro.find_elements(By.CLASS_NAME,'market-detail-list__row')
for i in range(sheet_max_row-1):
survey_word = sheet.cell(row=i+2, column=1).value #エクセルのA列から調査する項目取得
for mrow in market_d_list:
title_ele= mrow.find_elements(By.CLASS_NAME,'market-detail-list__small-name-title')
if len(title_ele)>0:
if title_ele[0].text==survey_word:
val_list=mrow.find_elements(By.CLASS_NAME,'market-detail-list__value')
sheet.cell(row=i+2, column=2).value=int(val_list[0].text.replace(',','')) #tokyo hi
sheet.cell(row=i+2, column=3).value=int(val_list[1].text.replace(',','')) #tokyo lo
sheet.cell(row=i+2, column=4).value=int(val_list[2].text.replace(',','')) #osaka hi
sheet.cell(row=i+2, column=5).value=int(val_list[3].text.replace(',','')) #osaka lo
sheet.cell(row=i+2, column=6).value= datetime.datetime.now() #取得日時
#エクセルに書き込み
wb.save(input_excelfile_name)
wb.close()
chro.close
messagebox.showinfo('処理終了','処理が終了しました')
if __name__ == '__main__':
main()
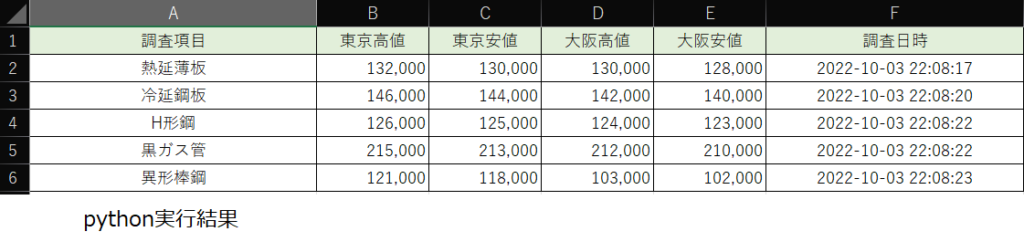
pythonでは44行のコードで下の画像のように結果が正しく取得でき、エクセルファイルに書き込むことができました。
エクセルVBAでの構築実例
次にExcelVBAでの構築を行います。
まずはSeleniumBasicをインストールします。

ファイルがダウンロードされますので、インストーラーに従ってインストールします。
インストール出来たら実行エクセルマクロファイルの設定を行います。
マクロを含むことのできるxlsm拡張子でファイルを作成して実行用ボタンを設置します。
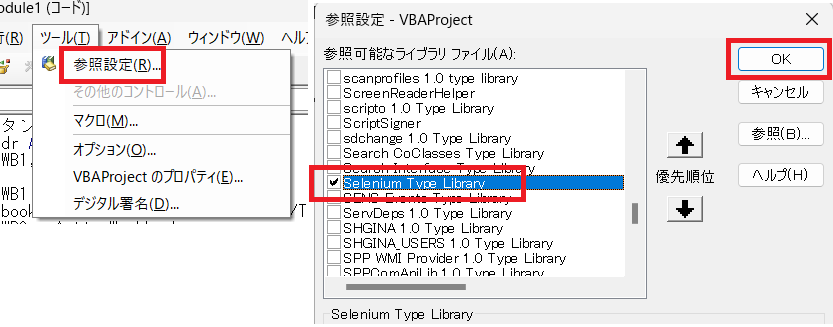
seleniumが使用できるように参照設定を設定します。
Selenium Type Livraryの項目にチェックを入れます。
コード内容はpythonと同じように記述していきます。(最後に正常に動いたコードを公開します。)
テスト実行したところオートメーションエラー’-2146232576(80131700)’が発生しました。
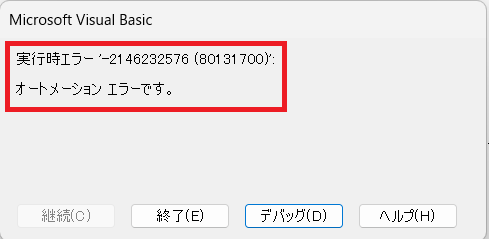
原因は「.NET Framework がインストールされていない」ことです。
c:\ユーザー名\AppData\Local\SeleniumBasic\Scriptsフォルダの中のStartChrome.vbsを実行します。
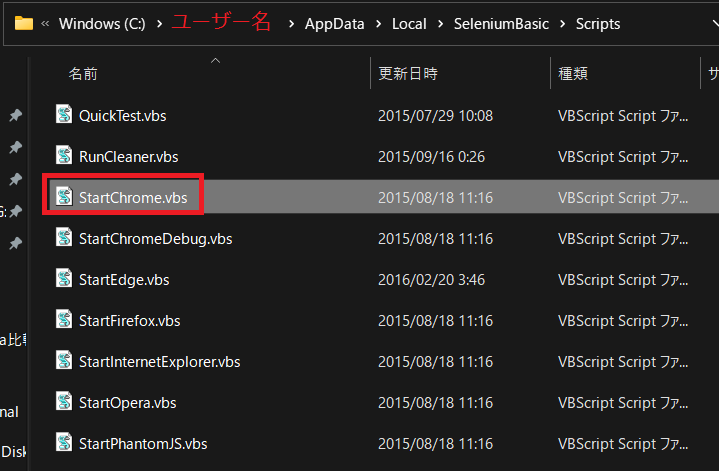
インストール画面が表示されますのでインストールを実行します。
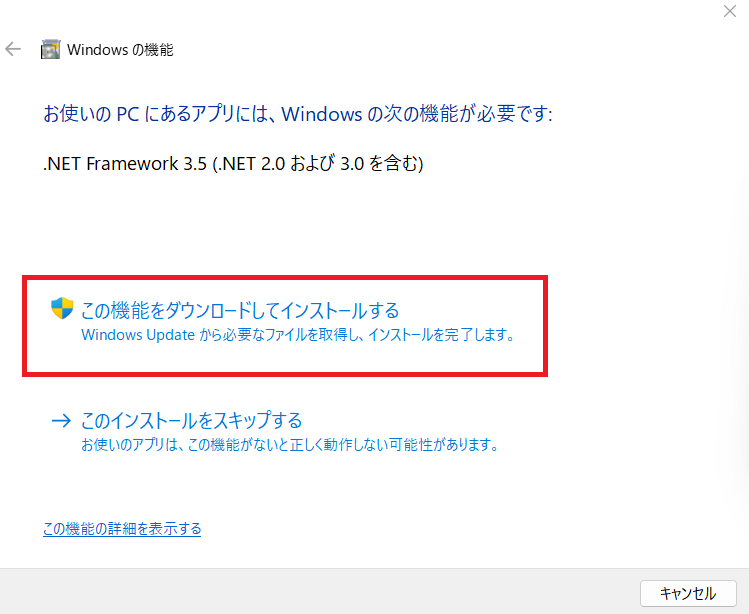
インストールが終わったら再度テスト実行してみます。
実行時エラー’400′ ArgumentErrorが出てしまいました。
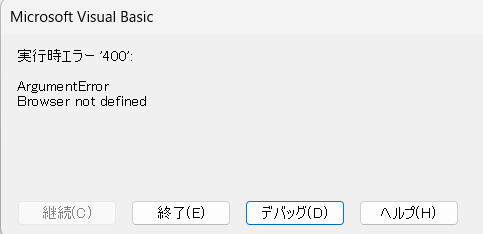
原因はコードの記述間違いでした。
誤) dr.start Chrome → 正)dr.start “Chrome”
再びテスト実行したところ別のエラーが発生しました。
Unknown error:cannot find Chrome binary(Driver info:chromedriver=2.21.371459)
クローム用のwebdriverのバージョンが古いようです。

自動でwebdriverを更新する方法を見つけることができました。
下記サイトからzipファイルをダウンロードして展開します。

SeleniumBasic対応のbasファイルをエクセルにインポートします。
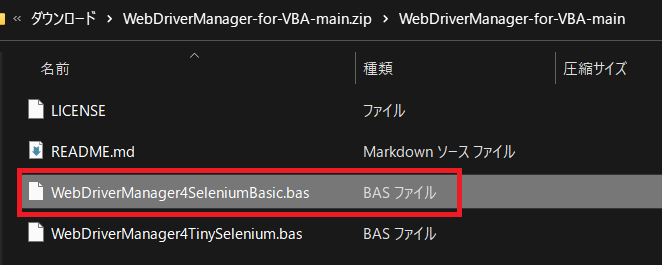
標準モジュールを右クリックして、ファイルのインポートをクリックするとダイアログがひょうじされるので、ファイル名を指定して開くをクリックします。
インポート成功すると基本モジュールの中にWebDriverManeger4SeleniumBasicが追加されます。
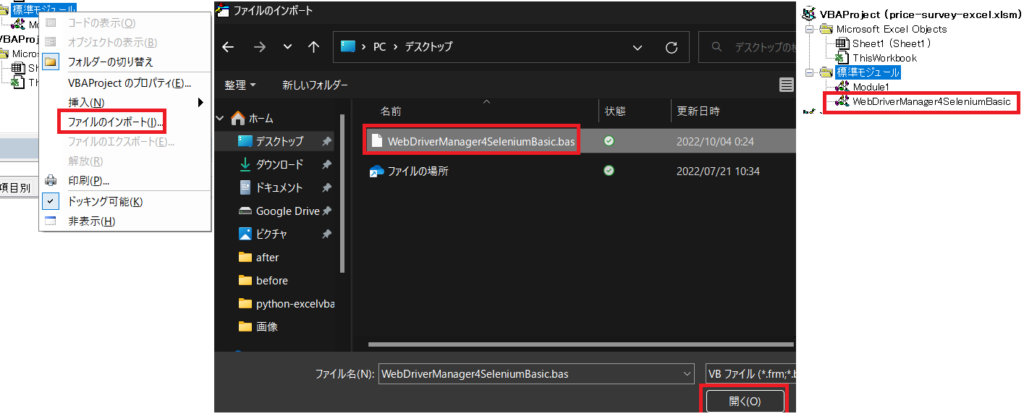
BASファイルをインポートしたので、ドライバー起動のコードを修正します。
(修正前)dr.start “Chrome” →(修正後)SafeOpen dr, Chrome
再度実行したところ正常に処理が完了しました。
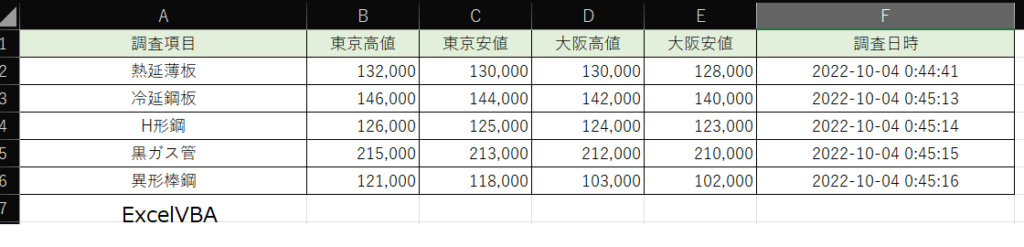
スクレイピングExcelVBAコード
それでは正常に動いた最終的なコードを公開します。
Sub ボタン1_Click()
Dim dr As New Selenium.WebDriver
Dim WB1, WB2 As Workbook
Dim DROW As Long
Set WB1 = ThisWorkbook
Workbooks.Open ThisWorkbook.path + "/TEST.XLSX"
Set WB2 = ActiveWorkbook
With WB2.Worksheets("データ")
SafeOpen dr, Chrome
dr.Get "https://www.japanmetaldaily.com/list/market/details"
Set market_d_list = dr.FindElementsByClass("market-detail-list__row")
DROW = 2
Do Until .Cells(DROW, 1).value = ""
For Each mrow In market_d_list
Set title_ele = mrow.FindElementsByClass("market-detail-list__small-name-title")
If title_ele.Count > 0 Then
If title_ele.Item(1).Text = .Cells(DROW, 1).value Then
Set VAL_LIST = mrow.FindElementsByClass("market-detail-list__value")
For I = 0 To 3
.Cells(DROW, 2 + I).value = VAL_LIST.Item(1 + I).Text
Next I
.Cells(DROW, 6).value = Now()
End If
End If
Next
DROW = DROW + 1
Loop
WB2.Save
WB2.Close
WB1.Activate
dr.Close
Set dr = Nothing
End With
MsgBox "取得完了"
End Sub
今回のseleniumプログラムの簡単な解説
公開したコードでは、seleniumの「クラス名」での要素取り出しを多用しています。
今回の鉄鋼新聞のページではクラス設定がされており、非常に簡単にデータが取得できました。
ExcelVBAのコードを例に簡単に説明していきます。
SafeOpen dr, Chrome
dr.Get "https://www.japanmetaldaily.com/list/market/details"
Set market_d_list = dr.FindElementsByClass("market-detail-list__row")1行目でchromeのバージョンに適合したwebdriverを取得して起動します。
2行目で鉄鋼新聞のURLを指定してウェブブラウザを起動します。
3行目で鉄鋼新聞のページの内容からクラス名を指定して要素を複数market_d_listに格納します。
クラス名を調べるにはウェブページの要素を右クリックして表示されるメニュー内の検証をクリックします。
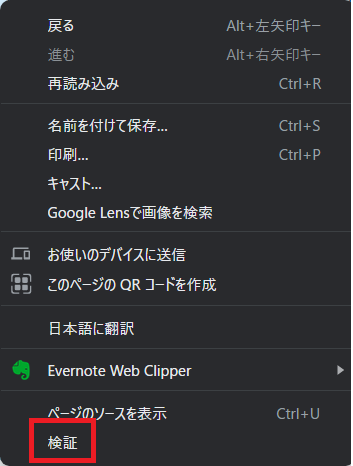
検証ボタンを押すとブラウザの右側にディベロッパーツールが起動します。
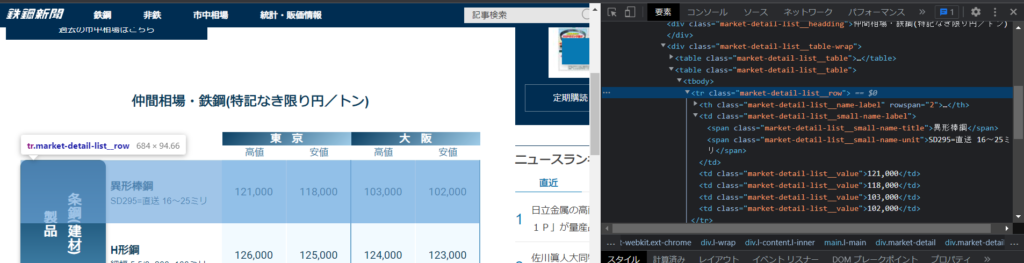
上の画像では異形棒鋼の行の要素がtr.market-detail-list_rowというクラス設定されていることがわかります。
鉄鋼新聞のこのページではH型鋼やほかの行もtr.market-detail-list_rowというクラスが設定されています。
その複数要素をリスト(配列)形式で抽出する関数がFindElementsByClass()です。
参考までに最初に見つかった要素1個だけを抽出するFindElementByClass()という関数もあります。
続いて、残りの金額を抽出してエクセルに転記する部分のコード解説をします。
Do Until .Cells(DROW, 1).value = ""
For Each mrow In market_d_list
Set title_ele = mrow.FindElementsByClass("market-detail-list__small-name-title")
If title_ele.Count > 0 Then
If title_ele.Item(1).Text = .Cells(DROW, 1).value Then
Set VAL_LIST = mrow.FindElementsByClass("market-detail-list__value")
For I = 0 To 3
.Cells(DROW, 2 + I).value = VAL_LIST.Item(1 + I).Text
Next I
.Cells(DROW, 6).value = Now()
End If
End If
Next
DROW = DROW + 1
Loop1行目から14&15行目のDo-Loopでtest.xlsxのA列に入力されている調査項目が空になるまで行を増分しながら繰り返します。
2行目のFor EACH INでmarket_d_listから1個ずつmrowに要素を取り出して13行目までの間に記述しているコードを実行します。
3行目ではmrowに入った要素の中からmarket-detail-list__small-name-titleという名前の要素をtitle_eleに格納します。
4行目でtitle_eleに格納された要素の数が0の場合には調査項目対象外の要素なので処理を飛ばします。
5行目でtitle_eleの要素のtextプロパティがtest.xlsxの調査項目に合致しているかを調べます。
合致していた場合には6行目以降で「東京高値、東京安値、大阪高値、大阪安値」の金額の要素をVAL_LISTに格納します。
7から9行目でFor文を使って、test.xlsxに数値を転記しています。
VAL_LIST.Item(1).Textで、東京高値の金額を取り出せます。
他のwebページではクラス設定がされていない場合もありますので、その場合にはFindElementByTag()やFindElementByName()等、ほかの要素抽出方法にて対応してください。
最後に
スクレイピングするには、環境構築の手間が少ないのでpythonをおすすめします。
ExcelVBAでも環境さえ整ってしまえば、スクレイピングは可能ですので、VBAが得意な方はVBAで挑戦してみてください。
私は、結果が同じであればどのような手段で自動化しても良いと思っています。
今回、yahooショッピングの最安価格を取得するつもりで記事を書き始めましたが、スクレイピング許可の確認をしたところ、前日までは大丈夫だったのに不可能になっていることに気づきました。
おそらく、yahooショッピングとpaypayモールが統合するので、変更になったのだと思います。
最初は大丈夫でも、時間が経過したらスクレイピング禁止になる可能性がありますので、皆さんも気を付けてください。
この記事以外にもExcelVBAやpythonの記事もありますので、参考になれば幸いです。




コメント